本章将针对Cache的工作过程与原理展开讨论
Cache信息地址编码
首先我们要意识到Cache的主要功能还是读写数据的. 既然是读写, 一定要有一套标准进行数据的储存和地址标注. 不同于内存的Address-Data对应模式, Cache独特的结构钢决定了它特殊的地址与数据的对应方式. Cache的数据调用机制主要归结于3+1部分: - Tag - Set Index - Block Offset - Valid Bit
其中Tag; Set Index; Valid Bit来自于从CPU处得到地址. 具体分布如下:  这三项指标确认了Process Address所对应的Cache中的位置. 而Valid Bit则作为一个指示信号代表着该位置是否有我们想要找的信息. 具体的Tag, Index, 和Offset的意义将会在下面详细讲解.
这三项指标确认了Process Address所对应的Cache中的位置. 而Valid Bit则作为一个指示信号代表着该位置是否有我们想要找的信息. 具体的Tag, Index, 和Offset的意义将会在下面详细讲解.
Cache结构 -- 地址指示
Cache的结构主要可以理解为: 数据地址被分为了很多Sets, 每个Set之间有很多Blocks, 每个Block中存储着数据, 然后我们根据指示从改Block中的信息中提取数据. 上一段我们提到了Tag, Set Index, Block Offset, 与Valid Bit. 他们的作用是: > Index: 选择哪一个Set > Block: 定位Set中的Block > Offset: 在Block中定位数据的位置 (Byte address within block) > Valid Bit: 查看Tag输入是否有效
下图很好的说明了Index, Block和Offset的工作机制. 从他们的提取, 到在Cache中的定位过程都有了细致的表述: 
Cache结构规划的时候, 我们可以定义其包括多少个Set. > Index的Size可以用\(log_2(NumberOfSets)\)来得出. > Offset的Size为\(log_2(NumberOfBytes/Block)\) > 而Size of Tag = Address size - Size of Index - Offset的Size.
Cache的结构根据Set数量等方面的不同, 可以划归为不同的类别. 实际上, 上图也是一个很典型的Direct Map结构, 我们在接下来将会讲到.
Cache结构 -- 部署形式
Cache分为三种结构形式: * Fully Associative: 每个Block有任意的位置 (Block can go anywhere) - Note: 没有Index项, 只有一个Comparator/Block * Direct Mapped: 每个Block只有一个位置 (Block goes one place) - Note: 只有一个comparator. Sets的数量和Blocks的数量相等 (Number of sets = Number of Blocks) * N-way Set Associative: 每个Block有N种可能的位置 (N places for a Block) - Note: N个Comparators. Sets的数量是Blocks数量处以N (Number of sets = Number of Blocks / N)
我们根据Blocks的数量和位置安排来确定Cache的基本结构
如下图所示. 最左侧的是每一个Address对应一个Block, 我们可以理解为地址中最末位的bit当作Block的指示部分. 中间列我们可以看到, 每一个地址的最后两个bits被视作是一组Block地址的指示部分, 每4个Block被分为“一组”(联想上面讲过的, 对应Set), 每一组的起始标志就是最后的两位地址重归“00”. 最后侧列中, 每个地址的最后三位bits被当作Blocks的指示部分. 每8个Block被当作一组(Set), 每一组的起始标志就是最后的三位地址重归“000”. 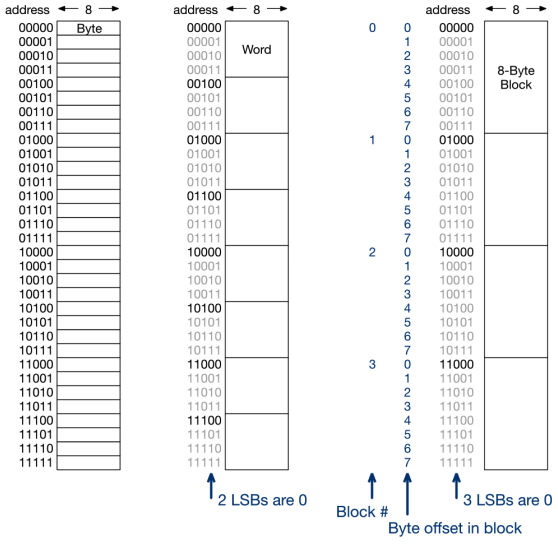
至于Block分组, 我们可以看作是将Address去mod(余数值)而确定的分布方式, 其理解示意图如下: 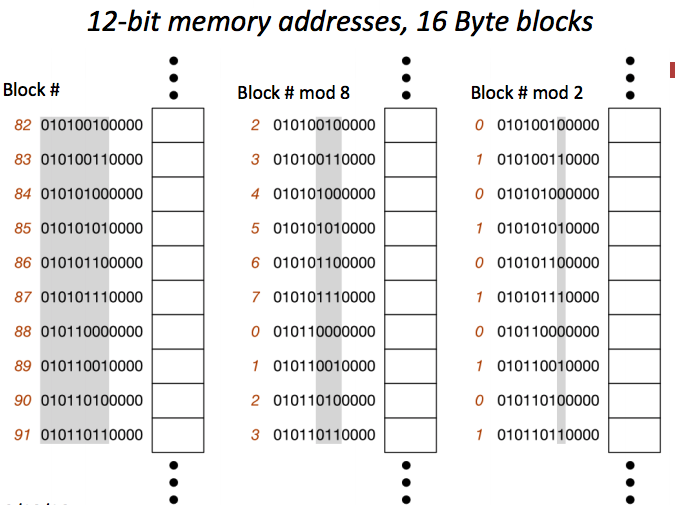
现在, 我们来系统的回忆一下Cache组成的格式和其运作的方式: 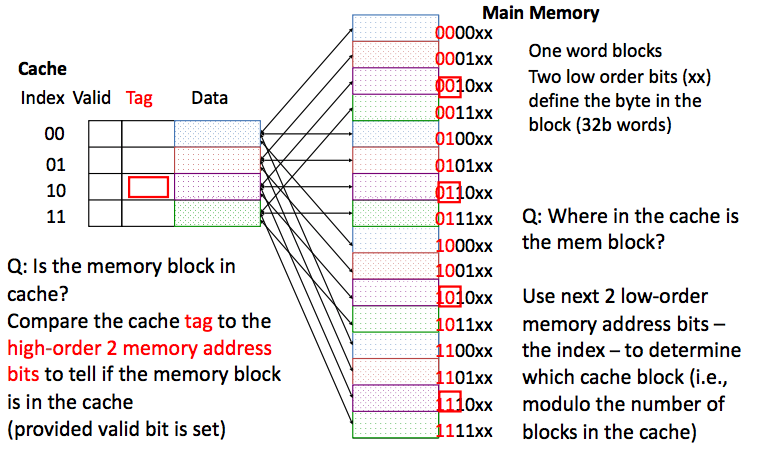
再看Valid Bit
在刚刚我们介绍Cache结构的时候, 貌似并没有提到Valid Bit的事情. 现在我们来回过头看Valid Bit的重要作用.
首先我们要注意的是, 当我们开启一个新的程序的时候, Cache没有关于这个程序的信息存储. 所以我们需要一个指示器(indicator)去告诉我们一个Tag Entry是否是有效的. 实际上, 在程序运行的过程当中, 因为我们可能存在同一个地址数据Overwrite的情况, 为了避免我们单纯依靠着地址信息去提取数据而出现的提取到了错误的数据的情况, 我们仍需要一个indicator去标示当前Tag是否有效. 这也就是我们Valid Bit的作用.
Valid Bit只有两个可能值: 0或1. > 0-> 自动Cache Miss, 哪怕碰巧Address = Tag > 1-> Cache Hit, 如果Processor Address = Tag
Cache结构 -- 解析
几类Cache结构(Direct Map; Fully Associative; N-way Set Associative)在刚刚都有做介绍. 本小段将略加细致的介绍其不同结构互动的部分与意义. 我们将从最基本的Direct Map, 了解其结构原理, 然后展开到其他Cache配置当中
Direct Map
Direct Map是Cache结构中最为简单的配置方式, 这种结构也被称为One-way Set Associative. 我们可以从多种性质来理解Direct Map, 这也是我们理解Cache的最基础与最直观的方式.
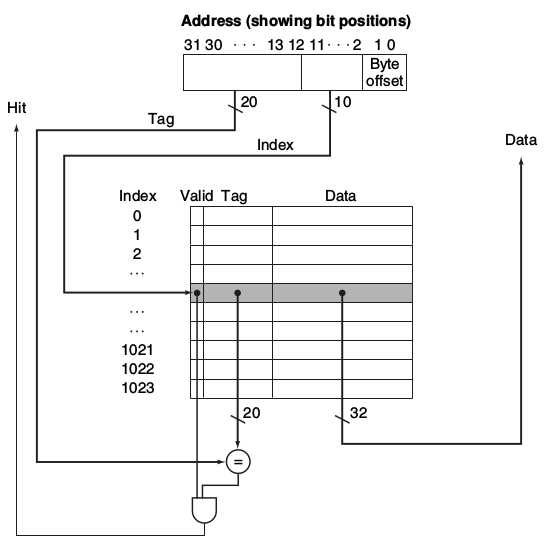
简单理解, Direct Map在位置信息上, 刚刚我们说过, 特点体现在Sets的数量和Blocks的数量相等, 也就是每一个Set对应着一个Block. 这样的情况下也就意味着我们将只需要一个comparator去确定data所在的地址信息(offset决定位置信息, 在如下图所示的Multiword-Block的情况, 也就是单个Block储存多词的情况). 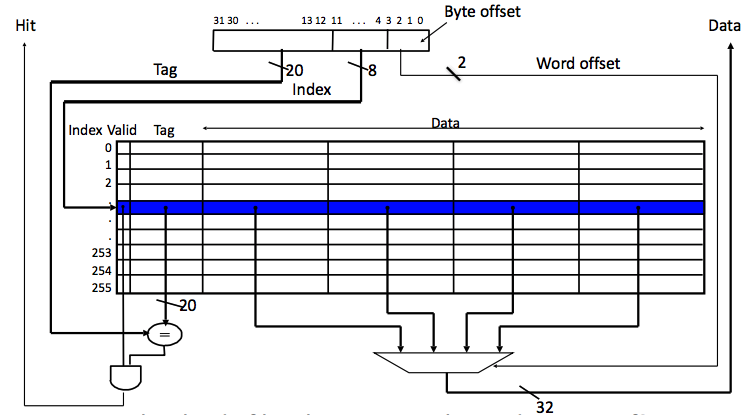
你可能会有疑问, 如果说我们只需要一种comparator去定位data的位置, 那么我们又要index和tag有什么用呢? 让换一种角度去看待Direct Mapped Cache形式. 这次我们关注与Cache与Memory之间的联系.
Direct Map就是将Memory中的信息平分然后分配给Cache的形式
从下图中我们可以看到, 我们将Memory中的数据完全平均分块, 然后对应进相对的Cache. 但是我们是如何分配的呢? 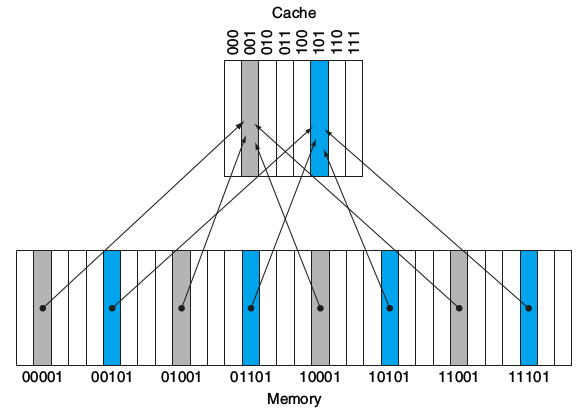
由图可见, 我们的Cache中有000~111共8个Block, Memory中有00000~11111共32个Block, 我们将Memory地址的后三个bits对应Cache的地址进行存储. 而前两位我们单独存储在tag中. 这样我们就完成了Address转译工作. > Note: 不要误认为我们是要将Memory的东西全部存入Cache, 我们只是介绍在Direct Map的结构下, 我们是如何用Cache的地址表示信息去表示对应Memory的Address的.
下图将能够更好的解释这个过程: 如图所示, Cache中有128个Block, 右侧是Memory, 有4096段信息. 由于\(\frac{4096}{128} = \frac{2^{12}}{2^7} = 2^5 = 32\). 我们设置Tag的范围为031(0000011111). 例如, 图中Cache中存储的第一个数据“384”可以理解为对应Memory中tag为3的Block的第0项的数据. 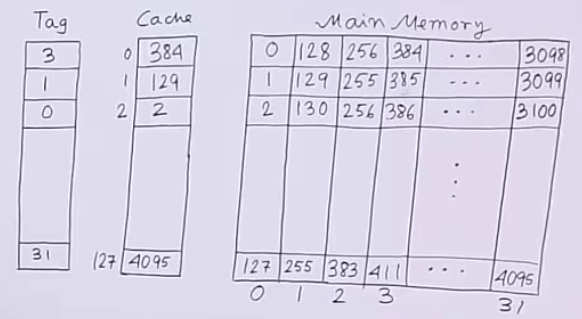
其他Cache配置
Cache配置的区别主要体现在Block的设置方面, 也就是我们所说的Set-Associaltive概念
所谓Set-Associaltive, 指的是将Cache分为几个Set, 其每个Set中包含一组Blocks. 在运行过程中, CPU将在指定Set中的每个Block中检查是否有 可用的/所需 的 地址/数据. 我们刚刚记述的Direct Map就是每一个Set中有1个Block的分配形式. 而N-Way Set-Associaltive就是每个Set中有N个Block的分配形式. 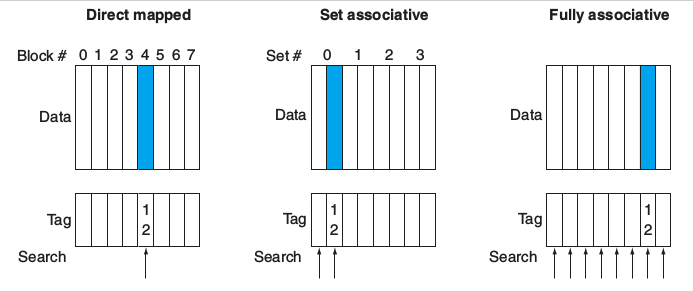
对于N-Way Set-Associaltive, 我们可以进一步形象理解: 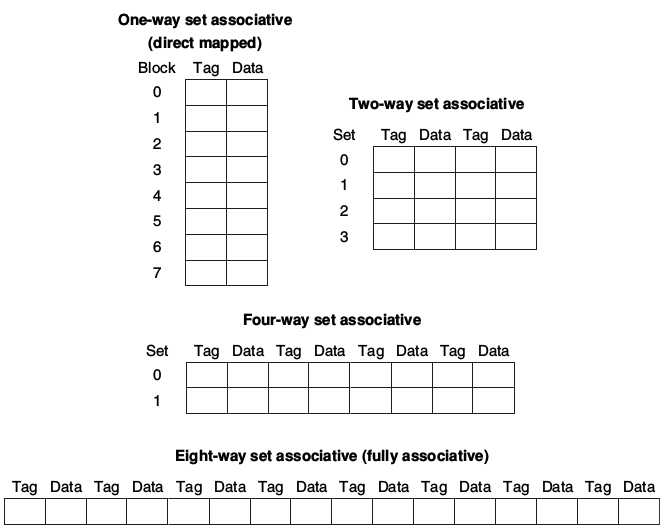
以下是某个实际的4-Way Set结构的Cache方式 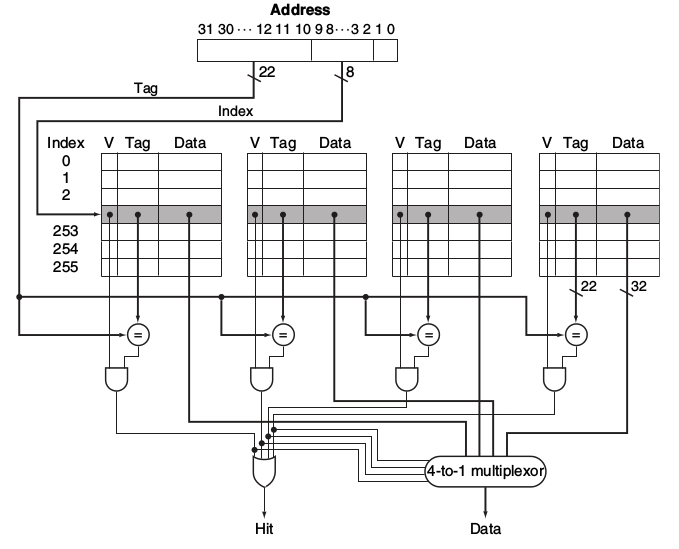
相信有了前面对Cache结构及功能理解. 我们对于Cache的运行方式和工作原理都有了比较清楚的认识.
Block Size与Miss Rate
Block Size
首先我们先回顾一下Cache存储的结构. 一般来讲, 因为一个Block不一定存储一个word而是多个, 假设每个Block中存储了\(2^m\)个word, 对应\(2^{m+2}\)bytes的资料大小. 所以一般来讲都会有m个地址bits被用来寻找是该Block中的哪个word, 另有2 bits用来寻找是该word的哪个byte. 在这里我们统称这些部分为Block Offset (本文初介绍).
通常我们将Cache内的资料作为Cache Size. 例如, 对于有1024个block的Direct-Mapped Cache, 其中每个block有4 byte的资料, 我们则视为其Cache Size为4KB.
例题: 使用32-bit的Address, 存放16KB的Data, 4 words/Block, 需要多大的Cache Size? 解: 16 KB = \(2^{14}\) bytes = \(2^{12}\) words -> (4 words/Block) -> \(2^{10}\) blocks. 因为使用32-bit address并且4 words/Block, 每个block储存数据4 * 32 = 128 bits. 根据上文中提到的计算Tag; Index; 和Offset Size的计算方法. 我们可知Index Size = \(log_2 2^{10} = 10\) bits, 并且Offset Size = \(log_2 128 = 7\) bits, 我们知道Tag Size = 32 - 10 - 7 = 15 bits. 加上一个Valid Bit, 于是我们总共需要\(2^{10} * (128 + 15 + 1) = 2^{10} * 144\) Kbits. [Note: 还有另外一种计算Tag Size的方式, 即Tag Size = 32 - Index Size - 2bit Word Index - 2bit Byte Index = 18 bits, 此种方式计算结果为147 Kbits]
Block Size与Miss Rate的联系
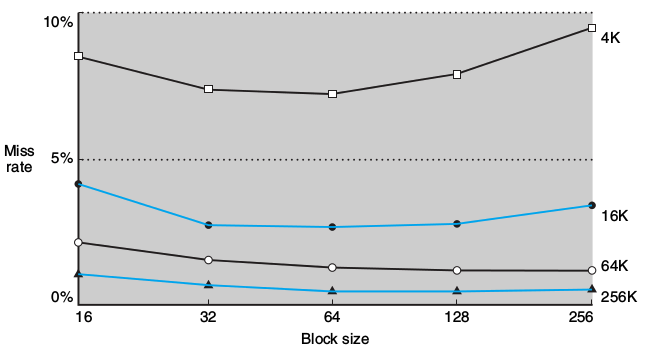 在相等的Cache Size下, Block Size的提升将导致Miss Rate下降, 因为我们提升了Spatial Locality (空间局部性). 但是过于提升Block Size将导致Miss Rate上升, 因为我们将导致Block的数量变少, 而Miss Penalty变大, 因为一旦Miss将Search更多的内容. 所以我们要在Block Size和Miss Rate之间找到平衡. 也就是我们要找到最合适的Cache结构形式, 或者说, 我们可以通过更改程序的设计来更好的匹配我们的Cache结构从而达到更佳的效率.
在相等的Cache Size下, Block Size的提升将导致Miss Rate下降, 因为我们提升了Spatial Locality (空间局部性). 但是过于提升Block Size将导致Miss Rate上升, 因为我们将导致Block的数量变少, 而Miss Penalty变大, 因为一旦Miss将Search更多的内容. 所以我们要在Block Size和Miss Rate之间找到平衡. 也就是我们要找到最合适的Cache结构形式, 或者说, 我们可以通过更改程序的设计来更好的匹配我们的Cache结构从而达到更佳的效率.
本系列Part 3将开始介绍Cache的读写运行机制